Землетрясение на IRK.ru
22 сентября 2020 в 2:06 в Иркутске случилось землетрясение. Какая была нагрузка на самый посещаемый сайт региона в связи с этим событием? И справился ли с ней сайт?
22 сентября 2020 в 2:06 в Иркутске случилось землетрясение. Я проснулся ночью за секунду до того, как стало трясти. У нас шаталась люстра и кровать. Но для целей нашего рассказа не имеет значение то, что происходило в момент землетрясения. Для нас имеют значения события, которые стали происходить сразу после землетрясения.
А именно.
Уже через десять минут мне позвонили и сказали, что у нашего новостного портала наблюдаются проблемы с доступностью.
Для неподготовленного читателя скажу, что я работаю руководителем техотдела сайта irk.ru - большого новостного портала.
В ту ночь все происходило примерно как в прошлый раз - люди кинулись смотреть иркру и искать информацию о землетрясении. Нагрузка нарастала лавинообразно. Вряд ли в этот раз я расскажу что-то новое, просто покажу цифры и озвучу свои мысли.
Нагрузка
Давайте посмотрим на лог-файл nginx и попробуем оценить пришедшую нагрузку. Мы будем пользоваться вот такой командой:
sudo cat /var/log/nginx/access-irk.log.1|grep "22/Sep/2020:02:18"|wc -lи постепенно меняя время, посмотрим, как распределялось количество запросов по минутам в ту ночь:
время в мин. в сек.
2:04 168 3
2:05 181 3
2:06 1076 18 <- землетрясение
2:07 2178 36
2:08 2890 48
2:09 4427 74
2:10 5348 89
2:11 6439 107
2:12 7347 122
2:13 8206 137
2:14 8203 137
2:15 8482 141
2:16 8500 142
2:17 8213 137
2:18 10333 172
2:19 5643 94Видно, что до землетрясения шла обычная ночная нагрузка - 3 запроса в секунду.
Потом, начиная с момента землетрясения в 2:06, трафик стал расти. Трафик вырос в пять раз в первую же минуту. А еще через 12 минут, в 2:18, к нам уже лилось по 170 запросов в секунуду. Это был пик.
Много ли это?
Смотря для чего. Наша база данных обрабатывает около тысячи операций чтения в секунду и глазом не ведет. Но для нашего веб-приложения, написанного на Django, которое на каждый запрос тратит время на рендер страницы, это серьезная нагрузка.

Появилась очередь из запросов и сайт стал тормозить. Часть людей так и не дожидались загрузки, нажимая крестик или перезагружая страницу. Когда очередь uwsgi переполнилась (она ограничена 100 запросов), Nginx просто стал показывать ошибку 502 вместо сайта.
Плохо. Очень плохо.
Особенно для меня - человека, который отвечает за то, чтобы тысячи людей вовремя получали нужную информацию на работающем сайте в любое время дня и ночи при любой нагрузке.
Но позвольте мне поднять от пола мои грустные глаза и продолжить рассказ. Ведь чтобы сделать лучше, нам нужно сначала понять, почему все так плохо.
Представим, что мы с вами отвечаем за сайт и хотим, чтобы он выдерживал такие нагрузки и не падал. Сколько серверов и какой мощности нам понадобится?
Ответ нам поможет найти
Немного математики
Возьмем среднее время рендера основных страниц сайта на бекенде:
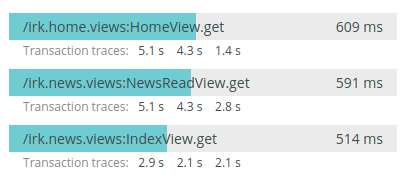
Из этого графика видно, что, например, главная рендерится целиком в среднем за 600 мс. Если у нас одно ядро процессора занято только обработкой страницы, то в среднем, в секунду, одно ядро может обработать только 2 запроса.
Сколько тогда нам с вами нужно ядер процессора, чтобы обслужить 170 запросов в секунду? Элементарно:
170 / 2 = 85 ядерОх. Это, например, сервер с двумя вот такими процессорам:
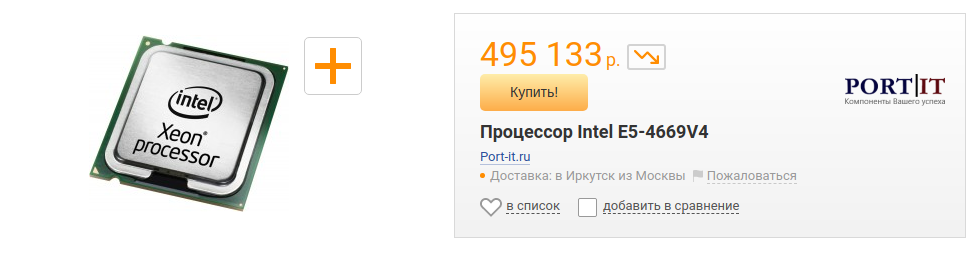
Каждый имеет 22 ядра, 44 потока. Два таких процессора как раз дадут нам 88 потоков.
Или это три сервера, как мы недавно преобрели.
Но как быть, если тратить на топовое оборудование миллион рублей не хочется, а обслуживать приходящие иногда пики нагрузки необходимо? Да и зачем нам такой процессор на постоянку, если у нас масштабные события происходят не каждый день?
Я вижу два пути: оптимизация бекенда и облако.
Облако
Теперь я наконец-то понял, зачем нужно облако. В ту ночь мы могли бы взять в аренду вот такой сервер:
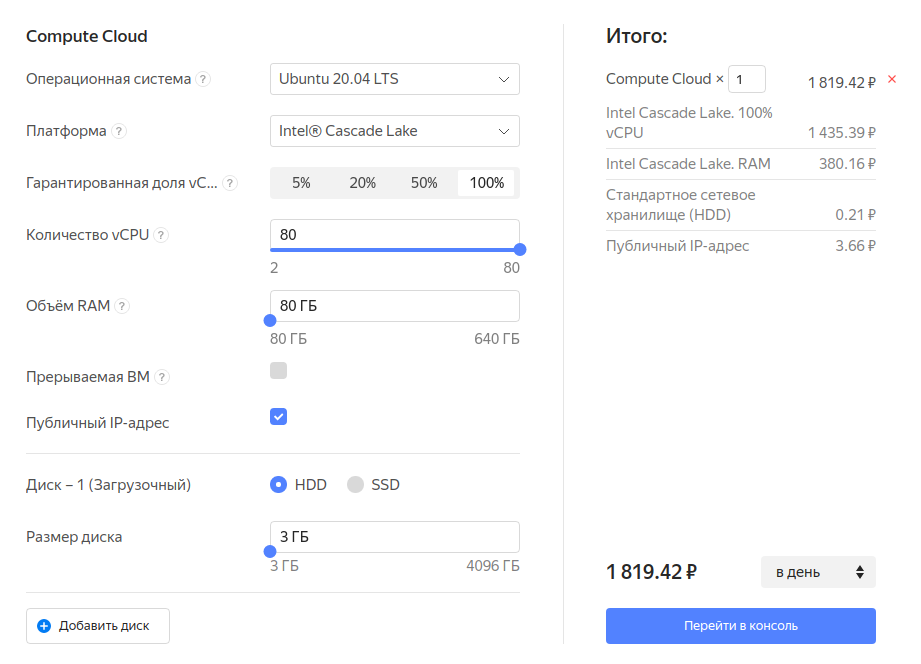
80-ядерный монстр за 1819 рублей в день. Взять на один день. Или даже на несколько часов, пока длилась большая нагрузка. А потом просто сдать этот сервер обратно одним нажатием кнопки, когда он перестал бы быть нам нужен.
Плюс облака в мгновенности: можно мгновенно взять нужное тебе железо и включить его в работу.
Конечно же, для этого нам нужны быстрые процедуры разворачивания сервера. Если бы я сразу подскачил с кровати в 2:06, у меня было бы всего 12 минут до пиковой нагрузки, чтобы успеть запустить новый сервер и включить его в работу.
Оптимизация бекенда
Второй путь - сделать так, чтобы главная создавалась за 300 мс, а не за 600. Тогда нам потребуется всего 40 ядер, что мы можем обеспечить даже имеющимся у нас не самым топовым оборудованием уровня HP Gen 8.
Еще мысли
Административный интерфейс лучше держать на отдельной машине.
Чтобы даже при большой нагрузке на основной сервер админка оставалась рабочей. Отдельный поддомен и отдельная машина - идеальное сочетание.
Сервер статики тоже очень важен - если люди не смогут загрузить styles.css, это будет равносильно тому, что сайт не откроется.
Что дальше
Будем работать над тем, чтобы можно было быстро развернуть воркеры бекенда в облаке. Будем оптимизировать страницы (это отдельная история). Будем думать о CDN.
Подписывайтесь на мою рассылку в форме ниже, я хотел бы видеть больше хороших людей в числе моих подписчиков, кроме тех хороших людей, что уже читают меня по электронной почте.